เมื่อความฉลาดเข้าใกล้ข้อมูลมากขึ้น ความเสี่ยงก็ใกล้ตัวมากขึ้น
บทนำ: Edge AI ที่ฉลาดขึ้น อาจเปราะบางขึ้นโดยไม่รู้ตัว
หนึ่งในเหตุผลหลักที่ทำให้ Edge AI ได้รับความนิยม คือความสามารถในการนำ AI เข้าไปใกล้ข้อมูลและหน้างานมากที่สุด ลด latency เพิ่มความเป็นส่วนตัว และทำงานได้แม้ไม่มีอินเทอร์เน็ต แต่คุณสมบัติเหล่านี้เอง กลับทำให้ Edge AI เผชิญความเสี่ยงด้านความปลอดภัยที่แตกต่างจาก Cloud AI อย่างมีนัยสำคัญ
ในระบบ Cloud ศูนย์ข้อมูลถูกปกป้องด้วยมาตรการความปลอดภัยระดับสูง แต่ Edge Device กลับตั้งอยู่ในโลกจริง อาจอยู่หน้าโรงงาน บนเสาไฟ ในร้านค้า หรือแม้แต่บนโต๊ะทำงาน การเข้าถึงทางกายภาพที่ง่ายขึ้น ทำให้คำถามเรื่อง Security และ Privacy ไม่ใช่เรื่องเสริมอีกต่อไป แต่เป็นแก่นของการออกแบบระบบ Edge AI ตั้งแต่วันแรก
บทความตอนนี้จึงชวนผู้อ่านมอง Edge AI ผ่านเลนส์ของ “ความเสี่ยง” และ “ความรับผิดชอบ” พร้อมแนวคิดและเครื่องมือที่ช่วยให้ระบบฉลาดได้ โดยไม่ละเลยความปลอดภัย
ภัยคุกคามเฉพาะของ Edge Device: เมื่อโลกจริงไม่ปลอดภัยเหมือนดาต้าเซ็นเตอร์
Edge Device แตกต่างจาก Cloud Server ตรงที่มันอยู่ในสภาพแวดล้อมที่ควบคุมได้ยาก อุปกรณ์อาจถูกถอด เปลี่ยน แก้ไข หรือดัดแปลงโดยไม่ได้รับอนุญาต การโจมตีจึงไม่ได้เกิดขึ้นเฉพาะในระดับซอฟต์แวร์ แต่รวมถึงระดับฮาร์ดแวร์ด้วย
ภัยคุกคามที่พบบ่อย ได้แก่ การโจมตีแบบ physical tampering การฝังมัลแวร์ผ่านอุปกรณ์จัดเก็บข้อมูล หรือแม้แต่การดึงโมเดล AI ออกไปวิเคราะห์ย้อนกลับ (model extraction) ซึ่งอาจนำไปสู่การละเมิดทรัพย์สินทางปัญญาและข้อมูลส่วนบุคคล (Tramèr et al., 2016)
นอกจากนี้ Edge AI ยังต้องเผชิญกับปัญหาการอัปเดตซอฟต์แวร์ที่ไม่สม่ำเสมอ หากอุปกรณ์จำนวนมากไม่ได้รับ patch ด้านความปลอดภัยอย่างต่อเนื่อง ช่องโหว่เพียงจุดเดียวอาจลุกลามเป็นความเสี่ยงระดับระบบได้
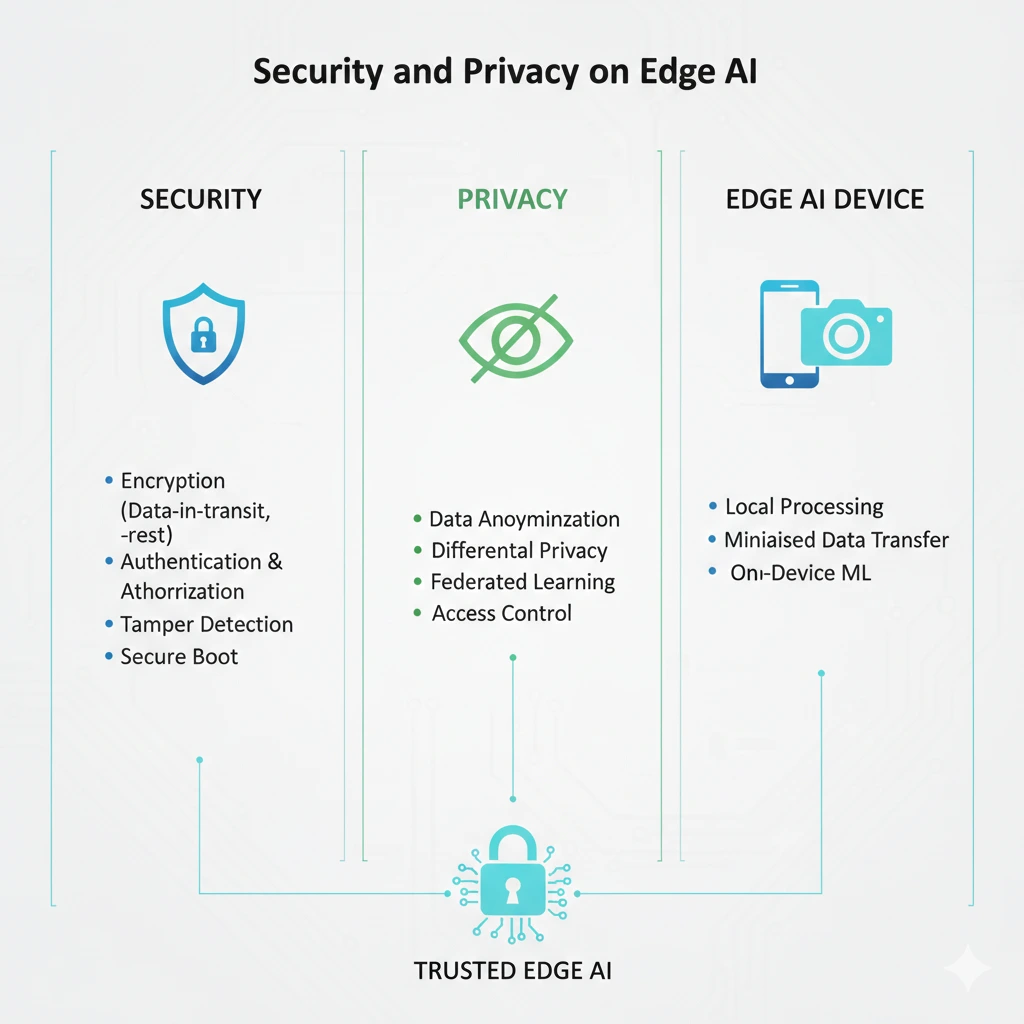
Privacy บน Edge: ใกล้ข้อมูลมากขึ้น ไม่ได้แปลว่าปลอดภัยโดยอัตโนมัติ
Edge AI มักถูกมองว่า “เป็นส่วนตัวกว่า Cloud” เพราะข้อมูลไม่จำเป็นต้องถูกส่งออกไปทั้งหมด แม้แนวคิดนี้จะถูกต้องในเชิงสถาปัตยกรรม แต่ในทางปฏิบัติ ความเป็นส่วนตัวยังคงต้องอาศัยการออกแบบที่รอบคอบ
ข้อมูลที่ Edge จัดการมักเป็นข้อมูลอ่อนไหว เช่น ภาพบุคคล เสียง หรือข้อมูลทางการเงิน หากอุปกรณ์ถูกเจาะหรือสูญหาย ข้อมูลเหล่านี้อาจรั่วไหลได้ทันที หลักการ privacy by design จึงมีบทบาทสำคัญ ตั้งแต่การเก็บข้อมูลให้น้อยที่สุด การเข้ารหัสข้อมูลทั้งขณะจัดเก็บและขณะส่งต่อ ไปจนถึงการกำหนดสิทธิ์การเข้าถึงอย่างชัดเจน (European Union, 2016)
ในโลกจริง การปฏิบัติตามกฎหมายคุ้มครองข้อมูล เช่น GDPR หรือ PDPA ไม่ได้เป็นเพียงข้อบังคับทางกฎหมาย แต่ยังเป็นปัจจัยด้านความน่าเชื่อถือของระบบ Edge AI ในระยะยาว
Federated Learning: เรียนรู้ร่วมกัน โดยไม่ต้องรวมข้อมูล
หนึ่งในแนวคิดที่ได้รับความสนใจอย่างมากในการแก้ปัญหา Privacy บน Edge คือ Federated Learning แทนที่จะส่งข้อมูลดิบไปฝึกโมเดลที่ศูนย์กลาง Edge Device จะฝึกโมเดลจากข้อมูลของตนเอง และส่งเฉพาะพารามิเตอร์ที่อัปเดตแล้วกลับไปยังเซิร์ฟเวอร์กลาง
แนวทางนี้ช่วยลดความเสี่ยงจากการรวมศูนย์ข้อมูล และเหมาะกับระบบที่มี Edge Device จำนวนมาก เช่น อุปกรณ์สวมใส่ ระบบสุขภาพ หรือระบบบัญชีที่มีข้อมูลกระจายตามสาขา (McMahan et al., 2017)
อย่างไรก็ตาม Federated Learning ไม่ได้แก้ปัญหาทุกอย่าง การออกแบบยังต้องคำนึงถึงความปลอดภัยของพารามิเตอร์ที่ส่งกลับ และการโจมตีเชิงสถิติที่อาจอนุมานข้อมูลต้นทางได้
Differential Privacy: ปกป้องข้อมูลด้วยคณิตศาสตร์
เพื่อเสริมความแข็งแรงให้กับ Federated Learning แนวคิดของ Differential Privacy ถูกนำมาใช้ โดยเพิ่ม noise ทางคณิตศาสตร์เข้าไปในข้อมูลหรือพารามิเตอร์ เพื่อป้องกันไม่ให้สามารถระบุตัวบุคคลจากผลลัพธ์ได้
Differential Privacy ช่วยให้ระบบ Edge AI สามารถเรียนรู้จากข้อมูลจำนวนมาก โดยลดความเสี่ยงในการเปิดเผยข้อมูลเฉพาะบุคคล แนวคิดนี้ถูกใช้อย่างแพร่หลายในระบบระดับองค์กรและภาครัฐ เช่น งานสำมะโนประชากรและระบบวิเคราะห์ข้อมูลขนาดใหญ่ (Dwork & Roth, 2014)
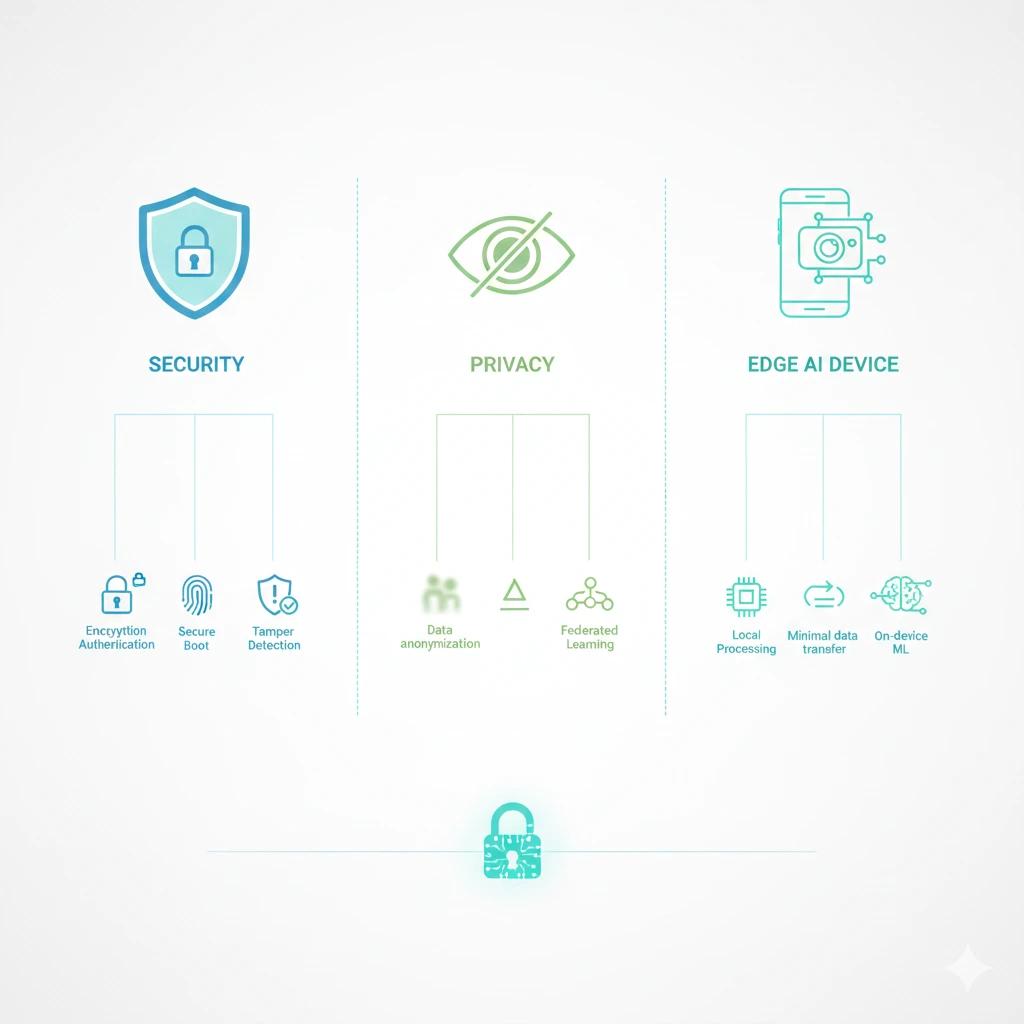
Best Practices: ความปลอดภัยไม่ใช่ฟีเจอร์ แต่เป็นกระบวนการ
การรักษาความปลอดภัยของ Edge AI ไม่สามารถพึ่งพาเทคโนโลยีใดเทคโนโลยีหนึ่งได้ แต่ต้องเป็นกระบวนการตั้งแต่การออกแบบจนถึงการใช้งานจริง แนวปฏิบัติที่สำคัญ ได้แก่ การใช้ secure boot การเข้ารหัสข้อมูล การแยกสิทธิ์การทำงานของระบบ และการตรวจสอบ log อย่างสม่ำเสมอ
ที่สำคัญไม่แพ้กันคือการออกแบบระบบให้สามารถอัปเดตและเพิกถอนอุปกรณ์ที่มีความเสี่ยงได้อย่างรวดเร็ว เพราะในโลกของ Edge AI ความเสียหายมักเกิดจากจุดเล็ก ๆ ที่ถูกมองข้าม
บทสรุป: Edge AI ที่ดี ต้องปลอดภัยพอ ๆ กับความฉลาด
Edge AI ทำให้ AI เข้าใกล้โลกจริงมากขึ้น แต่ยิ่งใกล้โลกจริงมากเท่าไร ความเสี่ยงก็ยิ่งเป็นรูปธรรมมากขึ้นเท่านั้น การออกแบบระบบ Edge AI ที่ประสบความสำเร็จจึงไม่อาจแยกเรื่อง Security และ Privacy ออกจากประสิทธิภาพและต้นทุนได้
เมื่อผู้อ่านตระหนักถึงภัยคุกคาม แนวคิดอย่าง Federated Learning และ Differential Privacy รวมถึงแนวปฏิบัติด้านความปลอดภัย จะสามารถออกแบบ Edge AI ที่ไม่เพียงทำงานได้ แต่ยังได้รับความไว้วางใจในระยะยาว
เอกสารอ้างอิง (References)
European Union. (2016). General Data Protection Regulation (GDPR).
Tramèr, F., Zhang, F., Juels, A., Reiter, M. K., & Ristenpart, T. (2016). Stealing machine learning models via prediction APIs. USENIX Security Symposium.
McMahan, B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017). Communication-efficient learning of deep networks from decentralized data. Proceedings of AISTATS.
Dwork, C., & Roth, A. (2014). The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science.